Wie wir für Wikimedia Deutschland die Zukunft des Freien Wissens untersucht haben – und welche Erkenntnisse wir daraus gewinnen konnten. Ein Beitrag von Simon Höher und Veit Vogel vom Hybrid City Lab.
Am 4. Mai 2020 wurde es offiziell: Wikimedia Deutschland startete erstmals einen eigenen Accelerator. Das Förderprogramm namens UNLOCK soll gute Ideen rund um das Thema Freies Wissen unterstützen. Die Initiative ist Teil von Wikimedias Globaler Strategie 2030. Alle, die bei UNLOCK mitmachen, werden dabei unterstützt, aus ihren spannenden Ansätzen echte Prototypen zu entwickeln. Damit das gelingt, bekommen die Teilnehmenden finanzielle Unterstützung, Coachings und Zugang zum Wikimedia-Netzwerk.
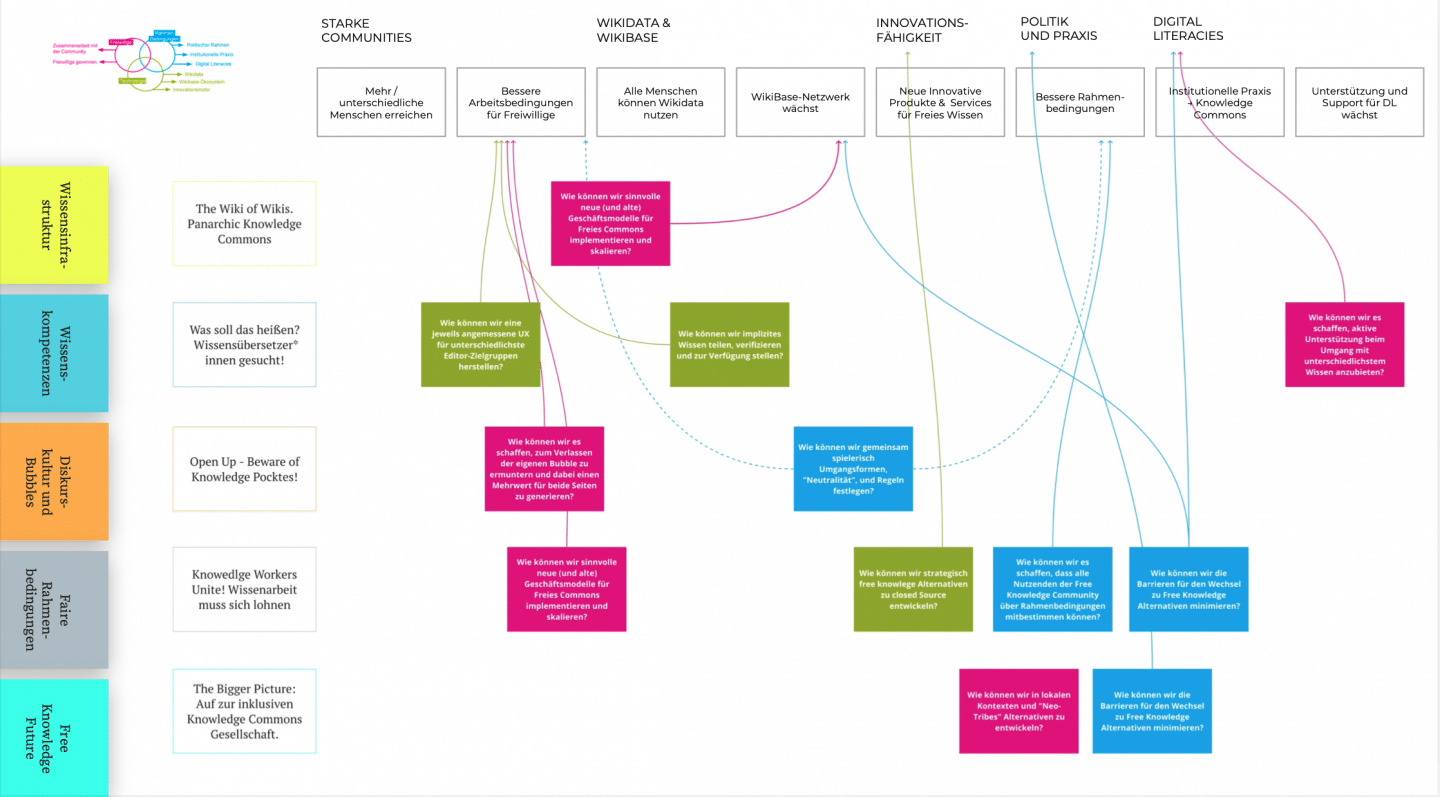
5 Themenfelder für Freies Wissen
Über drei Monate durften wir vom Hybrid City Lab die fünf Themenfelder des Accelerators mitgestalten. Wir führten Interviews, konzeptionelle Deep Dives und explorative Forschungssitzungen durch, um fünf greifbare Bereiche zur Förderung einer freien und digitalen Wissensgesellschaft zu identifizieren:
Wissensnetzwerke: Wie man existierende Wissensinseln besser verbinden kann.
Wissenskompetenzen: Wie man Wissen und den Umgang damit lernen kann.
Wissenshorizonte: Wie man Filterblasen zum Platzen bringen kann.
Wissensproduktion: Wie man fair mit Freiem Wissen umgeht.
Wissensgesellschaft: Wie wir eine große Bewegung für Freies Wissen erzeugen können.
Herausforderungen und Ziele
In diesem Blog-Beitrag wollen wir zeigen, wie wir dieses umfangreiche Thema bearbeitet haben und was wir selbst dabei gelernt haben. Der vollständige Ergebnis-Report ist hier online verfügbar.
Unsere zentralen Herausforderungen waren:
Sehr komplexes Thema: Der Bereich „Zukunft des Freien Wissens” ist extrem umfangreich. Er umfasst die Unterscheidung zwischen “Free” und “Libre”, berührt zahlreiche Daten-Themen, Diskussionen um Privatsphäre und vieles mehr. Daraus ergeben sich erkenntnistheoretischen Fragen, Überlegungen zu Zukunftsszenarien für die globale Zusammenarbeit und zahlreiche weiterführenden Fragen. Wir wussten, dass unsere Ergebnisse deshalb eine vorläufige Auswahl sein würden.
Starke Meinungen: Wir waren nicht die Ersten, die sich mit diesen Fragen beschäftigt haben. Das Streben nach einer digitalen und offenen Wissensgesellschaft ist mindestens so alt wie das Internet selbst. Viele erfahrene Organisationen, Aktivistinnen und Aktivisten und Projekte der letzten Jahrzehnte hatten ihren Anteil daran. Wikipedia ist sicherlich eines der prominentesten Beispiele dafür. Diese Vorgeschichte wollten und mussten wir berücksichtigen – für uns war es deshalb besonders wichtig, sorgfältig und respektvoll mit dem Thema umzugehen.
Systemische Ungewissheit: Zwar waren wir uns alle einig, dass wir dieses Feld so offen wie möglich angehen wollten, aber das bedeutete eben auch, dass wir zu Beginn nahezu keine Grenzen, konzeptionellen Zwänge oder Leitlinien hatten. Das funktionierte zwar in einem kleineren Team, aber wurde herausfordernder, als wir mit unseren Partnern diskutierten: Wir besprachen dann scheinbar willkürliche Kategorien, bevor wir diese überhaupt validieren konnten. Ein klassisches Henne-Ei-Problem offener Forschung – vor allem, wenn sie auf ein zukünftiges Szenario oder Ergebnis ausgerichtet ist.
Wir entschieden uns für einen qualitativen Ansatz mit wenigen, ausgewählten Interviews statt einer “erschöpfenden” oder “repräsentativen” Untersuchung quantitativer Erkenntnisse (wir glauben, dass es im Bereich des freien Wissens so etwas wie erschöpfende oder repräsentative Studien so gut wie nicht gibt). Wir konzentrierten uns darauf, unsere eigene Perspektive zu finden und unsere eigenen Prioritäten zu setzen. Vor diesem Hintergrund stellen wir hier einige Erkenntnisse und Best-Practice-Beispiele aus unserem Projekt vor:
Wir machen unsere eigenen Annahmen sichtbar – und verfeinern sie
Unser Team war von dem Projekt begeistert und voller früher Ideen, Erwartungen und Fragen. Also nahmen wir uns im ersten Schritt die Zeit, alles aufzuschreiben und unsere eigenen Annahmen zu überprüfen. Das schloss auch das Team des Kunden ein. Dabei kam eine noch etwas chaotische, aber erschöpfende Sammlung von (sehr) frühen Fragen und Antworten heraus. Auf dieser Basis konnten wir eine erste Gruppe von Themen finden, sie mit bestehenden Projekten und früheren Erkenntnissen verknüpfen und nach blinden Flecken suchen. Diese Sitzungen wiederholten wir mehrmals, notierten alle Eindrücke und testeten gemeinsam mit dem Team des Kunden (und sogar mit dessen Mitarbeiterinnen und Mitarbeitern), um unsere groben Kategorien zu verfeinern.
Wir arbeiten komplett ko-kreativ
Wir hatten das große Glück, mit einem fantastischen Wikimedia-Team zusammen zu arbeiten und einige wirklich wunderbare und inspirierende Expertinnen und Experten interviewen zu können. Im Grunde konnten wir unter freiem Himmel arbeiten: Wir führten alle Arbeiten, Synthesen, Datensammlungen, Interview-Notizen und sogar interne Diskussionen auf einem gemeinsamen Miro-Board durch. Dieses virtuelle Board war Notizblock, Kundenpräsentation, Kommunikationskanal und Brain Dump in einem. Das ersparte uns einerseits viel Hin und Her (und bereitete uns gut auf den Übergang in einen vollständig digitalen Arbeitsmodus vor), ermöglichte aber auch überraschende Interventionen, spontane Fragen und Kommentare anderer und eine organische “Projektgeschichte”, an die jeder anknüpfen konnte.
Wir unternehmen Deep Dives
Mit vielen individuellen Beiträgen, Best Practices und Geschichten unserer Interviewpartnerinnen und -partner unternahmen wir regelmäßige Deep Dives in methodologische, erkenntnistheoretische oder soziologische Bereiche. Das half uns dabei, einen soliden Rahmen für die weitere Kategorisierung zu schaffen – und inspirierte uns zu neuen und anderen Fragen. Die Deep Dives machten zwar alles komplexer, aber sie unterstützten uns auch dabei, keine Lücken zu übersehen.
Wir drehen Schleifen
Wo wir gerade bei komplex sind: Manchmal überwältigte uns die schiere Menge an Daten, wichtigen Fragen und Herausforderungen unserer Forschung. Wir brauchten mehrere Iterationen, um aus unseren Daten prägnante Erkenntnisse zu ziehen. Ganz ehrlich: Das war manchmal schmerzhaft. Bei jeder Iteration hatten wir das Gefühl, dass wir etwas Wichtiges ausgelassen haben, dass wir zu sehr vereinfachen oder eine Verbindung übersehen haben. Es war unglaublich hilfreich, kritische Feedback-Sitzungen mit dem UNLOCK-Team zu haben, um das Narrativ, die Klarheit und den Umfang unserer Ergebnisse zu testen.
Eine weitere Sache, die in dieser letzten Phase half, war die Einführung klarer Kategorien, um unsere Cluster vergleichbar zu machen. Die wiederkehrenden Fragen tauchen im Abschlussbericht auf: “Worum geht es”, “Was ist die Herausforderung”, “Was wird benötigt” und “Was ist bereits vorhanden”. Auch hier haben sich Struktur und Inhalt bzw. Form und Funktion iterativ mitentwickelt.
Wir ziehen eine Grenze
Wo zieht man die Grenze angesichts einer so offenen Fragestellung? Abgesehen von den sehr realen Projekt- und Zeitbeschränkungen beim Start des Programms selbst erwies sich die Recherche als eine Art Luxus: Wir haben eine erste Zusammenfassung der zentralen Punkte und Themen erstellt und der Bericht wurde im Meta-Wiki des Accelerators veröffentlicht. Unser Report soll ein lebendiges Dokument sein. Und hier schließt sich der Kreis: Das Projekt und das Thema an sich lädt alle dazu ein, selbst Deep Dives zu machen, den Bericht durchzulesen, ihn zu ergänzen, zu redigieren und darauf aufzubauen. Wer weiß, vielleicht bildet dies die Grundlage für die nächste Version. Wir jedenfalls würden uns freuen, weiter zu lernen.
Wir danken dem wunderbaren Team von Wikimedia Deutschland e. V. für ein inspirierendes Projekt, den großartigen Menschen und Partnern, die ihre Erkenntnisse in Interviews und Mails mit uns geteilt haben, und wir können es kaum erwarten, zu sehen, was als nächstes kommt – durch den Accelerator und darüber hinaus!
Das Hybrid City Lab ist das Urban and Public Design Studio von zero360. Das Team entwickelt gesellschaftliche Innovationen und hilft öffentlichen Organisationen, faire und lebenswerte Orte im digitalen Zeitalter zu schaffen – in der Stadt und weit über sie hinaus.
Der vollständige Artikel ist in englischer Sprache unter dem Titel “Strategic research in vast complexity” auf medium.com einzusehen.
Wir verwenden Cookies auf unserer Website, um Ihnen die beste Erfahrung zu bieten, indem wir Ihre Präferenzen speichern auch bei wiederholten Besuchen. Durch Klicken auf "Akzeptieren" stimmen Sie der Verwendung aller Cookies zu. Sie können jedoch die Cookie-Einstellungen aufrufen, um eine kontrollierte Einwilligung zu erteilen. Mehr Informationen finden Sie auch in unserer Datenschutzerklärung
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. However you may visit Cookie Settings to provide a controlled consent.
Diese Website verwendet Cookies, um Ihre Erfahrung zu verbessern, während Sie durch die Website navigieren. Von diesen Cookies werden die nach Bedarf kategorisierten Cookies in Ihrem Browser gespeichert, da sie für das Funktionieren der Grundfunktionen der Website unerlässlich sind. Wir verwenden auch Cookies von Drittanbietern, mit denen wir analysieren und nachvollziehen können, wie Sie diese Website nutzen. Diese Cookies werden nur mit Ihrer Zustimmung in Ihrem Browser gespeichert. Sie haben auch die Möglichkeit, diese Cookies zu deaktivieren. Das Deaktivieren einiger dieser Cookies kann sich jedoch auf Ihr Surferlebnis auswirken.
This website uses the open source web analysis service Matomo for statistical analysis of website usage.
We also use the Matomo “Heatmaps” function, which analyzes movements of the mouse cursor and interactions with elements and thus provides particularly useful information on the use of the site.

{kind=link}
{kind=link}